





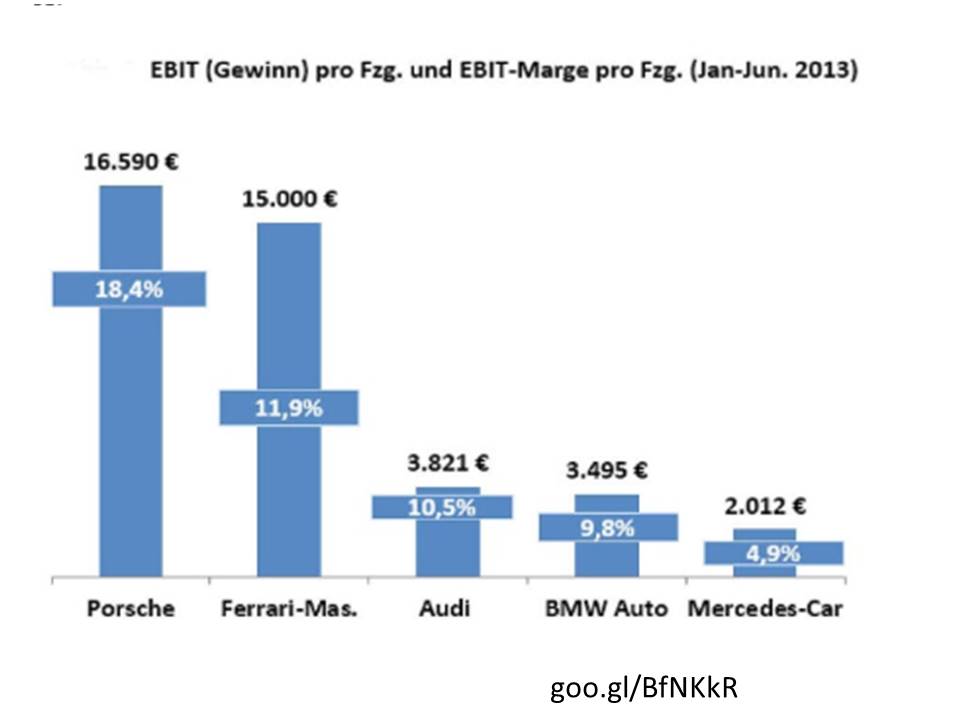























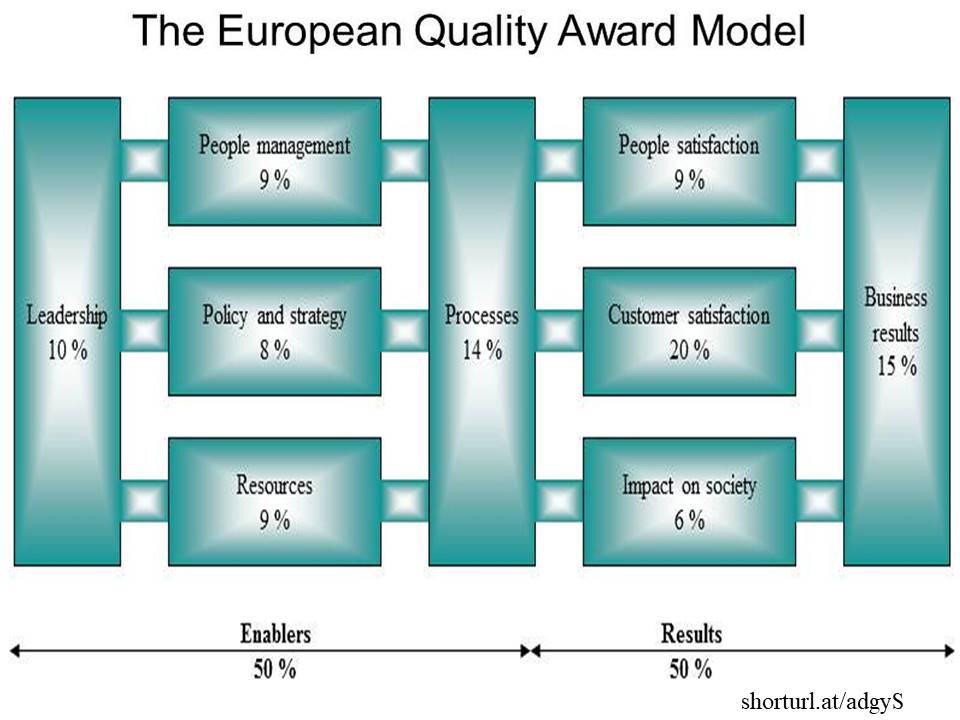





Prezados Colegas,
Estamos iniciando o treinamento virtual do Laboratório de
Ciência de Dados e Gestão Sistêmica da USP em Piracicaba, no dia 6/6/2020 das 15 às 18 horas, mandaremos e-mail com o link da reunião no Google Meet. Já fizemos
alguns treinamentos presenciais, reuniões
para organização e realizamos vários trabalhos nessas áreas, coloco no Anexo 1
alguns slides ilustrando.
Como poderão ver nos slides estamos realizando trabalhos há três
anos utilizando machine learning (inteligência artificial), em diversas áreas
como produção de alimentos, ecologia aplicada, economia e administração, agora
estamos entrando na área de medicina, por causa da Covid-19, tentando colaborar
com o combate à pandemia. Nas áreas de estatística aplicada, computação e gestão
trabalhamos há mais de 25 anos, com centenas de trabalhos realizados.
Estamos percebendo que a área de machine learning é muito
versátil, podendo ser aplicada em praticamente todos os trabalhos de pesquisa.
Logicamente a estamos utilizando com prudência, sempre checando resultados com
a estatística. Já fizemos varias apresentações em congressos, publicamos
artigos, estamos orientando três trabalhos e coorientando outros dois de
pós-graduação e ganhamos um premio no
final do ano passado, primeiro premio em autenticidade de qualidade de
alimentos da revista Food Chemistry, de impacto 5,4 (titulo: .....). O primeiro
de machine learning, já tínhamos seis premiações ou menções honrosas na área de
gestão sistêmica. No Anexo 2 colocamos links de blogs onde podem visualizar
mais informações de nosso trabalho, como videoaulas, apostilas, tutoriais, etc.
Aplicamos os conhecimentos do Laboratório em 4 disciplinas de graduação e 3 de
pós-graduação da USP de Piracicaba.
Estamos buscando aumentar a massa critica para incorporar
novas experiências de aplicação, podermos estudar em maior profundidade e
acompanhar as novidades dessa área que acontecem o tempo todo, como também
acontece na área de gestão sistêmica e estatística. Nosso enfoque é aplicado,
estudamos a teoria necessária para utilizar com critério as tecnologias.
Partiremos do zero nos treinamentos nas duas áreas, não é
necessária nenhuma base previa, pretendemos ter uma sequencia de aprendizado
gradual. Em paralelo organizaremos treinamentos para diferentes níveis de
qualificação.
A sequencia de treinamentos gradual será gratuita, podemos
montar cursos extra pagos, para poder remunerar colaboradores e comprarmos
hardware e software. No momento estamos bem equipados.
O laboratório é um produto da inteligência coletiva e
colaborativa, com espirito solidário. O sistema organizacional depende da
vontade dos colaboradores, gostamos da gestão participativa e do estilo de gestão
Y de Douglas Mc Gregor.
Esperamos contar com sua participação.
Prof.
Gabriel Sarriés
LCE/ESALQ/USP
Anexo 2 - Blogs onde podem encontrar mais informações de
nosso trabalho:
- Blog do Laboratório de Ciência de Dados e Gestão Sistêmica
- Blog da Disciplina LCE0137 – Para todos os cursos de
graduação da USP em Piracicaba (7)
- Blog da Disciplina LCE5736 – Para todos os cursos de pós-graduação
da USP em Piracicaba (mais de 20)
##
Anexo 1 – Slides Ilustrativos
##



Source | DF | Sum of Squares | Mean Square | F Value | Pr > F |
Model | 3 | 129.8000000 | 43.2666667 | 36.24 | <.0001 |
Error | 11 | 13.1333333 | 1.1939394 | ||
Corrected Total | 14 | 142.9333333 |









| Obs | cat | imc | corr | kcal |
|---|---|---|---|---|
| 1 | AT | 20.2 | 60.7 | 3200 |
| 2 | AT | 21.3 | 54.8 | 3100 |
| 3 | AT | 19.3 | 49.6 | 2800 |
| 4 | AT | 21.1 | 52.3 | 3300 |
| 5 | SEM | 22.4 | 14.9 | 2600 |
| 6 | SEM | 21.9 | 17.8 | 2700 |
| 7 | SEM | 23.8 | 18.6 | 3200 |
| 8 | SEM | 24.1 | 15.1 | 3300 |
| 9 | SE | 27.3 | 2.5 | 2700 |
| 10 | SE | 23.4 | 4.3 | 2300 |
| 11 | SE | 25.2 | 2.3 | 2600 |
| 12 | SE | 26.4 | 2.6 | 3200 |
| 13 | PR | 26.2 | 4.1 | 2600 |
| 14 | PR | 24.2 | 2.1 | 2700 |
| 15 | PR | 25.4 | 1.9 | 2650 |
The GLM Procedure
| Class Level Information | ||
|---|---|---|
| Class | Levels | Values |
| cat | 4 | AT PR SE SEM |
| Number of Observations Read | 15 |
|---|---|
| Number of Observations Used | 15 |
The GLM Procedure
Dependent Variable: imc
| Source | DF | Sum of Squares | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| Model | 3 | 63.99233333 | 21.33077778 | 14.23 | 0.0004 |
| Error | 11 | 16.49166667 | 1.49924242 | ||
| Corrected Total | 14 | 80.48400000 |
| R-Square | Coeff Var | Root MSE | imc Mean |
|---|---|---|---|
| 0.795094 | 5.214802 | 1.224436 | 23.48000 |
| Source | DF | Type I SS | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| cat | 3 | 63.99233333 | 21.33077778 | 14.23 | 0.0004 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| cat | 3 | 63.99233333 | 21.33077778 | 14.23 | 0.0004 |

The GLM Procedure
Dependent Variable: corr
| Source | DF | Sum of Squares | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| Model | 3 | 6829.158500 | 2276.386167 | 300.25 | <.0001 |
| Error | 11 | 83.397500 | 7.581591 | ||
| Corrected Total | 14 | 6912.556000 |
| R-Square | Coeff Var | Root MSE | corr Mean |
|---|---|---|---|
| 0.987935 | 13.60410 | 2.753469 | 20.24000 |
| Source | DF | Type I SS | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| cat | 3 | 6829.158500 | 2276.386167 | 300.25 | <.0001 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| cat | 3 | 6829.158500 | 2276.386167 | 300.25 | <.0001 |

The GLM Procedure
Dependent Variable: kcal
| Source | DF | Sum of Squares | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| Model | 3 | 497333.333 | 165777.778 | 1.95 | 0.1801 |
| Error | 11 | 935000.000 | 85000.000 | ||
| Corrected Total | 14 | 1432333.333 |
| R-Square | Coeff Var | Root MSE | kcal Mean |
|---|---|---|---|
| 0.347219 | 10.18210 | 291.5476 | 2863.333 |
| Source | DF | Type I SS | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| cat | 3 | 497333.3333 | 165777.7778 | 1.95 | 0.1801 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
|---|---|---|---|---|---|
| cat | 3 | 497333.3333 | 165777.7778 | 1.95 | 0.1801 |

The GLM Procedure

The GLM Procedure
Duncan's Multiple Range Test for imc
This test controls the Type I comparisonwise error rate, not the experimentwise error rate.
| Alpha | 0.05 |
|---|---|
| Error Degrees of Freedom | 11 |
| Error Mean Square | 1.499242 |
| Harmonic Mean of Cell Sizes | 3.692308 |
Cell sizes are not equal.
| Number of Means | 2 | 3 | 4 |
|---|---|---|---|
| Critical Range | 1.983 | 2.075 | 2.129 |

The GLM Procedure

The GLM Procedure
Duncan's Multiple Range Test for corr
This test controls the Type I comparisonwise error rate, not the experimentwise error rate.
| Alpha | 0.05 |
|---|---|
| Error Degrees of Freedom | 11 |
| Error Mean Square | 7.581591 |
| Harmonic Mean of Cell Sizes | 3.692308 |
Cell sizes are not equal.
| Number of Means | 2 | 3 | 4 |
|---|---|---|---|
| Critical Range | 4.460 | 4.665 | 4.788 |

The GLM Procedure

The GLM Procedure
Duncan's Multiple Range Test for kcal
This test controls the Type I comparisonwise error rate, not the experimentwise error rate.
| Alpha | 0.05 |
|---|---|
| Error Degrees of Freedom | 11 |
| Error Mean Square | 85000 |
| Harmonic Mean of Cell Sizes | 3.692308 |
Cell sizes are not equal.
| Number of Means | 2 | 3 | 4 |
|---|---|---|---|
| Critical Range | 472.3 | 494.0 | 507.0 |